Optimizing Algorithms for Bitcoin Script (part 3)

This is the third and final part in a series of articles. The first article detailed how I implemented an optimized version of SHA256 using lookup tables, and the second demonstrated the use of the Stack Tracker library. I encourage you to read both articles before this one. In this article, I’ll explain how the BLAKE3 algorithm works and how I used the Stack Tracker to optimize the on-chain implementation of the BLAKE3 cryptographic hash function.
BLAKE3 Algorithm
BLAKE3 is a cryptographic hash function, similar in purpose to SHA256, but it was designed to be much faster due to its ability to parallelize part of its computations and its choice of internal operations. In the “Right Rotate” sub-section we will look at how the choice of the number of bits to shift a number impacts on the performance.
Why use it? The main reason to use BLAKE3 instead of SHA is its much smaller implementation size on Bitcoin Script. The version of SHA256 using StackTracker consumes 297K opcodes, while BLAKE3 only uses 75K opcodes per round.
Unlike SHA256, for which there are numerous resources to help understand the algorithm, BLAKE3 has fewer readily available resources. I relied on the Rust and Python reference implementations, as well as Bitcoin Script created by the BitVM team (now, while writing this article, I’m reading the BLAKE3 paper itself and it’s quite clear).
How it works
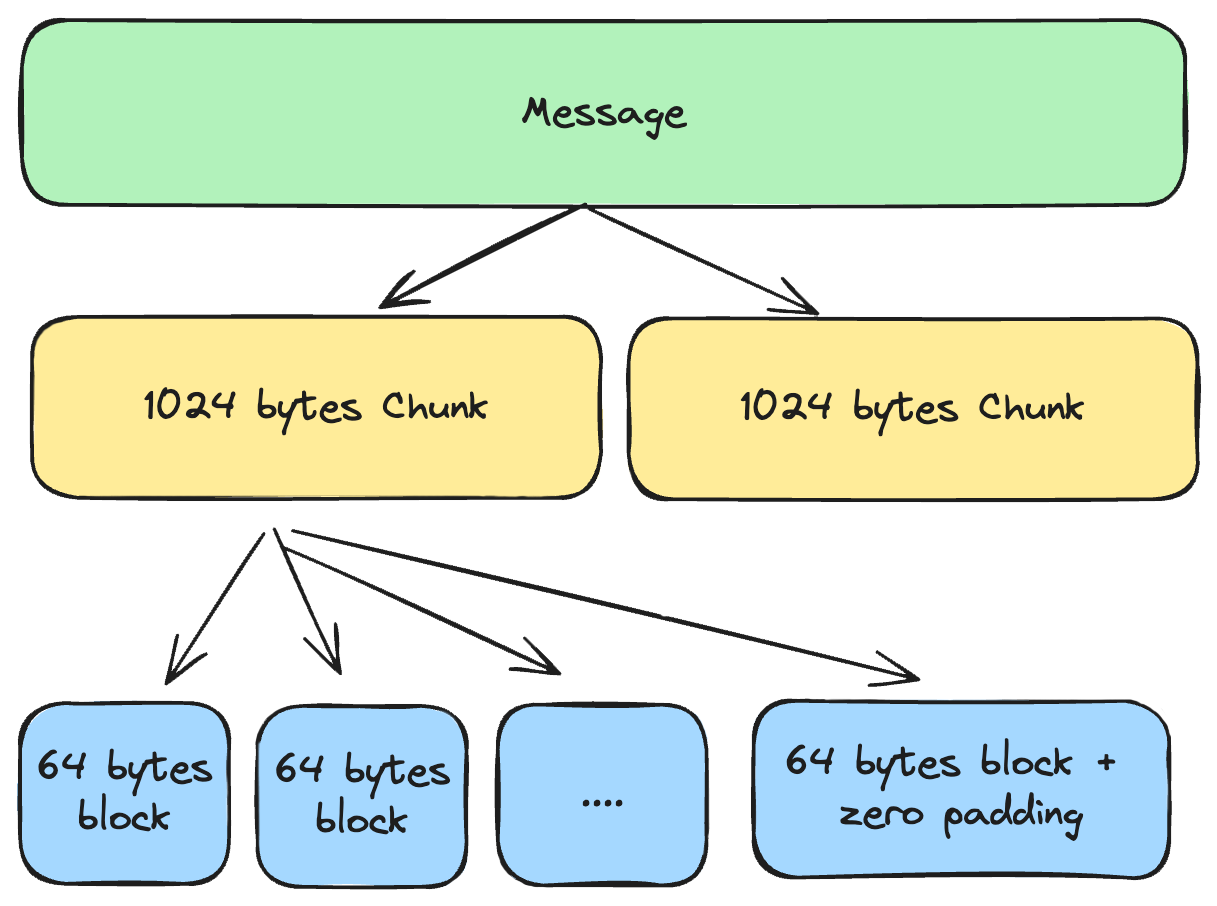
BLAKE3 achieves its high performance through parallelization by creating a tree structure. The hash function splits the message in chunks of 1024 bytes. However, in the context of using BLAKE3 on-chain, we would never have more than 1024 bytes (not even close) due to the stack size limit, so this implementation does not handle the tree structure.
The algorithm supports three different hashing modes. One is used for regular hashing, and the other two are designed to support an extra key, but the last two modes were not implemented in this version either because they will probably not be needed.
Each 1024-byte chunk is divided into 64-byte blocks that are processed sequentially in a chain. These 64 bytes are handled as 16 words of 32-bit unsigned integers. If the last block contains less than 64 bytes, it is zero-padded to fill the block.
Pseudocode
Let’s take a look at BLAKE3 pseudocode:
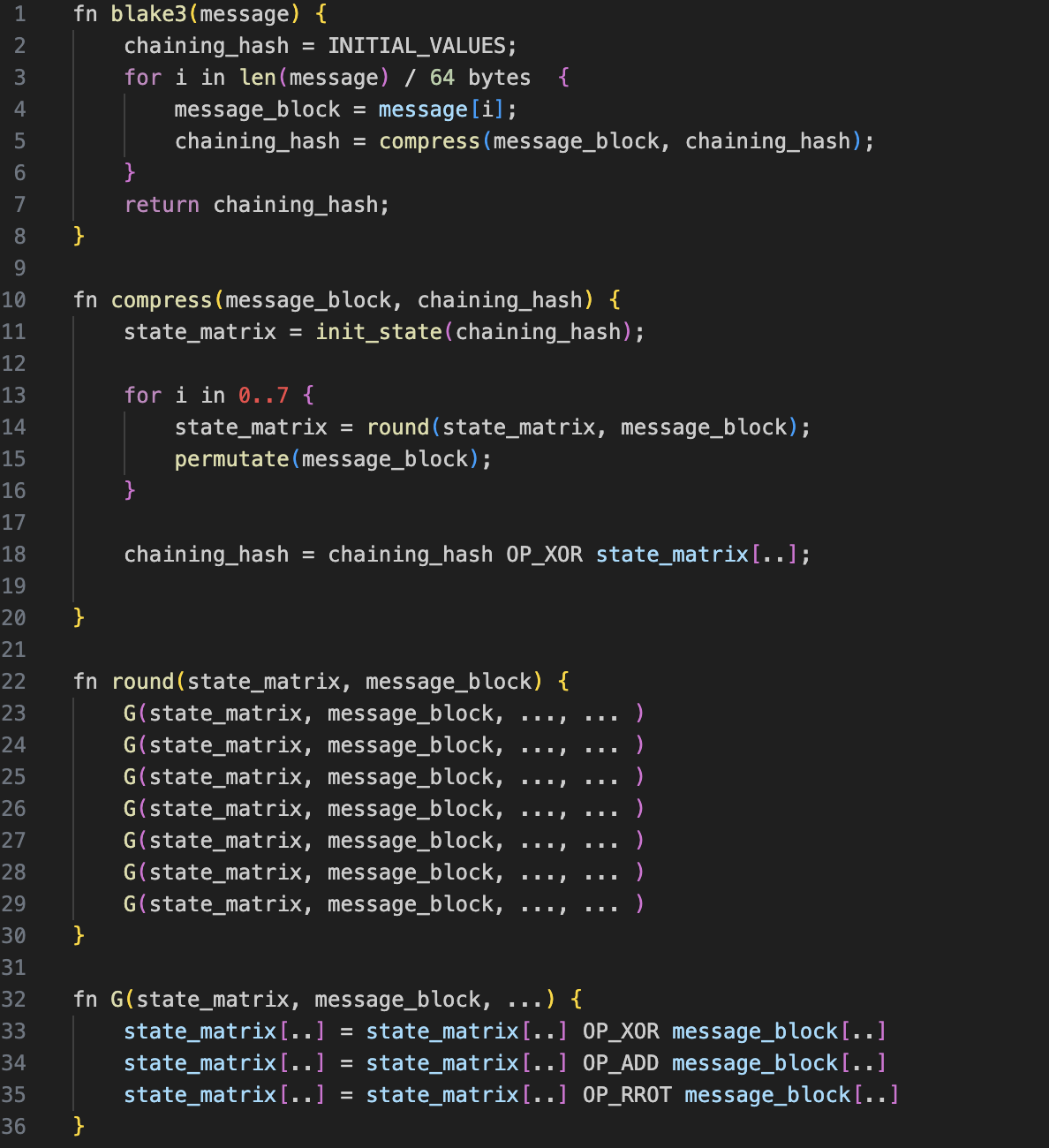
(The "..." in this code indicates the presence of certain constant values that have been removed to improve readability.)
The algorithm is quite simple. as it essentially loops through the call of a function that. in turn, calls a sub-function in a loop.
- The blake function splits the message into 64 bytes blocks and calls compress for each block.
- The compress function initializes a state, calls the round function 7 times and calculates the output hash, which is used as chain input for the next block or as the resulting hash after the last block.
- The round function will call 8 times the G function, processing different parts of the message block with the state.
- Finally, the G function performs the actual operations over the data, using three key operations: XOR, 32 bit addition and right rotate.
Implementation
The Bitcoin Script implementation is provided here and it follows the structure and function naming of the pseudocode.
The operations performed by the G functions are described in this image taken from the paper:

All of these operations are performed using lookup tables and operate on nibbles.
Lookup Table Management
To perform operations using lookup tables, the table data needs to be loaded into the stack and unloaded after use. Since loading and unloading tables is costly in terms of operations, it’s a good idea to load all the necessary tables at the beginning and unload them once they are no longer needed.
It's important to note that dropping elements from the stack is only possible when the element is at the top, so keeping the stack organized is crucial for efficient element removal.
In some cases, the 1,000-element stack limit makes it impossible to keep all the tables in memory. When this happens, but the lookup table is used frequently, it might still be worthwhile to pay the cost of loading and unloading the table to reduce the overall script size.
As you can see in this snippet, there is a struct that manages all the lookup tables used in the BLAKE3 implementation:
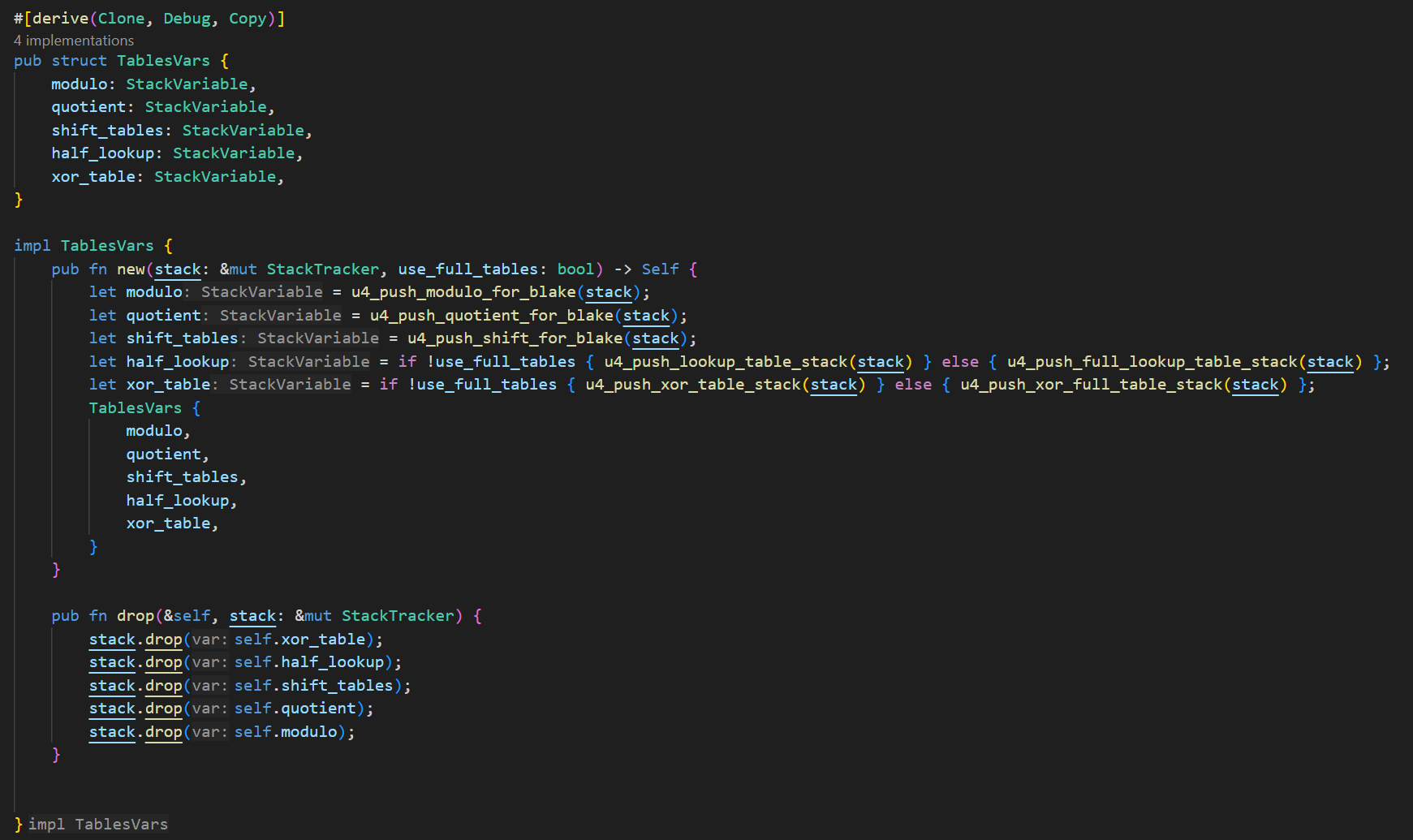
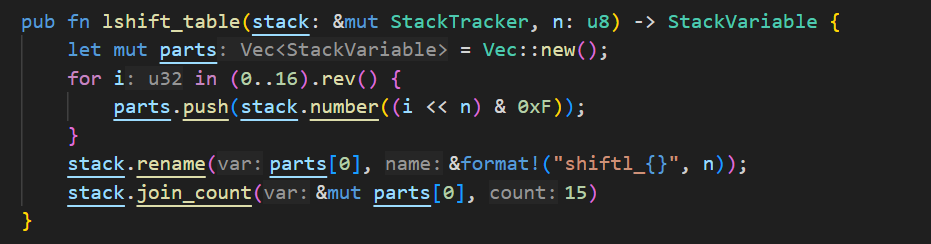
In this implementation, the u4_push_*** functions contain the actual values for the tables, which were generated using Python. However, as an example of how to generate one of these tables directly in Rust, take a look at this example function that generates left shift tables:
Addition
To solve addition, two tables are used: one for modulo and one for quotient. The table supports adding three numbers simultaneously (as opposed to adding two numbers, and then adding the third to the result). This approach reduces the number of times the lookup table needs to be used and minimizes the movement of elements in the stack.
Right Rotate
Unlike SHA256, where the bit rotation counts are odd, three of the four rotation counts in BLAKE3 are multiples of 4. Since we are working with nibbles (4 bits), these bit rotations can be achieved by simply rearranging the elements of the u32 number, without the need for any additional operations or lookup tables.
For the remaining rotations of 7 bits, we only need to rotate by 3 bits, since we are working with 4-bit integers ( 7 mod 4 = 3 ). To perform 3-bit right rotation, two tables are used: one to shift right by 3 bits, and another to rotate left by 1 bit.
XOR
To calculate XOR two modes are used depending on the length of the message to be hashed and the available room in the stack. If the message is short, the “full” XOR table is used. For long messages, the “half-table” is applied.
The full table consumes more stack space but requires fewer opcodes to compute the result. Conversely, the half-table uses less stack space but requires more Bitcoin opcodes, which increases the overall script size.
Combining Operations
If you explore the code, you will notice functions named right_rotate_xored and right_rotate7_xored. The purpose of these functions is to combine the XOR and rotation operations simultaneously, reducing the cost of moving and rearranging the nibbles twice.
Permutations
One step in the algorithm requires permuting the words of the message. Since moving variables around the stack is costly, our code does not actually move any part of the message. Instead, it modifies a map that points each variable to the correct position. This creates an indirection between the permuted indices and the actual variables on the stack, allowing for efficient handling without the overhead of rearranging the stack.
Summary
In this series of articles, I demonstrated how using nibbles and lookup tables to optimize functions in Bitcoin Script resulted in a significant reduction in script size—around 30% for both SHA256 and BLAKE3. I also introduced the Stack Tracker library, which simplifies the process of writing and debugging Bitcoin Scripts by providing tools for managing stack operations more efficiently.
I hope you enjoyed this series and that it has inspired you to think about new and creative approaches to writing Bitcoin Scripts.