Latest Innovations in BitVMX
During this last month we have been researching and coding. Why keep researching? Because BitVMX is a new technology and there is much more to be discovered. This is the first of a series of articles on improvements to the BitVMX protocol. After careful analysis of their pros and cons, we may implement some of these key new ideas in the BitVMX codebase. Overall, we’re super excited. In fact, some of these ideas may deserve full papers. In this article we start by analyzing improvements related to the removal of the protocol's second n-ary search.
From two n-ary searches to one
One of the distinct properties of the BitVMX protocol is that it replaces the use of state Merkle trees proposed for BitVM1 (and used in all optimistic rollups), for a second interactive n-ary search protocol. In this phase, the protocol searches for two consecutive steps, where the first is incorrect and the second is correct. This occurs within a specific range of the trace; between the last instruction that writes to a memory location and the instruction that (incorrectly) reads a different value from it.

[img 1]The figure shows BitVMX binary search for two consecutive steps (w-1,w) where the first is incorrect and the second is correct.
We have nothing against the Merkle tree data structure in itself, but verifying updates to a Merkle tree in Bitcoin script is more error prone than a simple hash chain. Simplicity generally implies greater security. Merklizing the memory also has the drawback of expanding the memory requirements 10X for the verifier. The downside of not using a Merkle tree is that we need more protocol rounds to perform a second n-ary search. The challenge is how to remove this second search without memory expansion. We attempted to do it using other authenticated data structures and we came up with three novel solutions.
Recall that in BitVMX, the validity of a computation is based on protocol participants comparing hash chains obtained from a program's execution trace. Each instruction's "step hash" is obtained recursively, by appending the previous step's hash to the current trace, and then hashing the result. To save space, the step hashes are restricted to the first 20 bytes of the hash digests.
Let’s briefly describe the problem we need to solve in a simplified form: there are three steps in the execution trace (t, q and q+1 in the figure). The first step (t) claims to write a value to a memory location. The second step (q) is simply a correct step, and the third step (q+1) claims to read a different value from the location written by the first step. The prover and verifier agree that the second step (q) is correct because they agree on its trace step hash, but they don’t agree on the first or third trace step hashes. The verifier wants to prove that the first step hash is wrong. The second step already references the first step hash through the hash chain, so the verifier can show that the first step is wrong by simply presenting all steps hashes in-between. However, This is too costly, as a hash chain doesn’t provide efficient non-interactive inclusion proofs. That’s why in BitVMX the parties engage in an interactive protocol for this proof. Now imagine we are allowed to redesign the contents of the step hash chain so that the second step indirectly references the first step in a way that allows efficient interactive proofs. We also require to keep the amount of data hashed per step hash low, preferably lower or equal to 56 bytes, to be able to prove a wrong hash efficiently in Bitcoin script. We present three solutions to this problem.
The Trace Merkle Tree
Our first idea was to use a Merkle tree of step traces and let each step in the step hash chain additionally commit to the Merkle root of this tree (updated up to that step, and filling all future branches with the zero hash). For n steps, the verifier only needs to store log2(n) hashes in memory during program execution, and each execution step must evaluate up to log2(n) hashes. The new step hash becomes the hash of 3 components: the previous step hash (20 bytes), the step trace Merkle root (20 bytes), and the step write trace, fitting nicely in 56 bytes with 80-bit security.
| Previous step hash | Trace tree root hash | Step trace |
[img 2] The new step hash format adding a Merkle trace tree root.
Non-terminal nodes in the Trace Tree need only to hash 40 bytes (left and right node hashes).

[img 3] On the left, a partial trace tree for step 2. On the right, the full Trace tree.
We now must solve two problems: first, the third step (q+1) can now be invalid not only because of any of the previous reasons (invalid memory reads, invalid step execution, etc.) but also because it has an incorrect trace root, so we must be able to easily and efficiently prove that the trace root is incorrect. Since the parties have agreed that the previous step is correct (step q), the verifier only has to prove that, given the tree referenced in the previous step, adding a new leaf leads to a new trace tree root that contradicts the prover’s claim in the step hash (q+1). We call this the append proof. The append proof requires one party revealing log2(n) hashes onchain, and letting the other party challenge the append verification process, so it’s a single round subprotocol. It’s not difficult to code the verification of an append proof in a standard programming language, but it is more difficult to do in Bitcoin script. Several corner cases must be carefully considered.

[img 4] On the left, the state of the trace tree at step 2. On the right, the state on step 3 after the tree has been updated. The highlighted nodes were added, and the prover or challenger must provide the node hashes, so that the other party can challenge any midstate of the update process.
The second problem is to create the inclusion proof of a first step trace in the tree specified by a second step trace root. This is done by the verifier or the prover by showing a Merkle path from the root to the leaf corresponding to the first step. The proof only requires posting log2(n) hashes. Once a party commits and signs all these Merkle hashes, the other party is allowed to challenge any of them, and then the first party must disclose a complementary hash to show the correct computation of that node in the tree. The whole inclusion proof subprotocol takes one round.

[img 5] On the left, a Trace Merkle tree and the nodes used to provide a Merkle inclusion proof. On the right, those nodes are serialized to be published in a transaction for the other party to be able to challenge them.
The Skiplist
The second idea was much more daring: what if we replace the step hash chain with an authenticated data structure that can connect any two steps in the trace in a logarithmic number of hash digests? One link always connects to the prior step, so we have only one extra link left per step. Proving that a new step has been correctly added (knowing that the prior step is correct) would be as simple as computing onchain which step number is to be referenced by the extra link, and providing an inclusion proof from the correct step down to this step number.
Why must each step hash only reference two prior steps and not more? To be able to challenge those hash evaluations onchain, we want messages hashed to be short and fixed-size, preferably below 64 bytes.Three back-links would consume at least 60 bytes, not leaving root for the trace itself.
It seems that there is already a data structure that can be tweaked to do this: a skiplist. A skiplist allows the connection of any two nodes (steps in our case) in logarithmic number of hops. Apart from each node pointing to the previous one, there are “lanes” which allow some nodes to skip over many nodes. Every two nodes there is a lane 1 that connects them, every four nodes we have lane 2, and so on. The higher the lane number, the further it jumps. But lookups are logarithmic provided that we can move between lanes in constant time. As the lanes of a node are generally implemented with a vector of pointers, this is not a problem. But in our case, because we want the skiplist to be authenticated, we must tweak it. We could hash a variable number of pointers, but then the hash function itself would be too long to fit in a taproot script, and we would need to be able to challenge intermediate states of such long hash function computation, or, alternatively, put the pointers in a Merkle tree, and let the other party challenge a path, but these solutions add huge complexity to the protocol.
If we stick with fixed-sized messages for the hash functions, moving between lanes will have a cost of a hash evaluation. We replace each pointer vector with a hash chain of the different lane pointers. To allow switching lanes, all pointers must reference the node itself and they cannot reference other lane pointers.

[img 6] One possible design for an authenticated skiplist. Some links of lane 1 have been removed because they don’t provide any shortcut. Each box represents a 2:1 hash function compression.
You can see that the problem with this adaptation of the skiplist is that inclusion proofs are not logarithmic anymore, but log(n)^2, because an inclusion proof may require up to 2log2(n) jumps using lanes, and reaching a specific lane requires traversing all the prior lanes in the lane chain, which are, in the worse case, also log2(n). For large n values, such as 232 , the difference is huge. log2(n) is 32, but log2(n)2 is 1024. The authenticated skiplist has been used successfully in blockchain before, such as in the NiPoPow protocol, but in that protocol the goal is to minimize data transferred, not to minimize (and simplify) the hash function evaluations.
The Jumplist
Because the skiplist doesn’t provide logarithmic inclusion proofs, we created a new authenticated data structure we call the jumplist, where each node only references two previous nodes, the one immediately preceding it (the short jump) and the extra one chosen according to a function (the long jump). The function that selects the long jump distances is easy to code but nontrivial to design. The following figure shows a graph of 64 nodes representing a jumplist, where nodes are connected using short and long jumps.

[img 7]A 64 node jumplist (short jumps in black, and long jumps in blue).
We’ve designed the function to select long jump targets based on considering the binary representation of each step number, and splitting that binary number in two intervals, a data interval (most significant bits), a counter interval (less significant bits). The counter emulates the moving between lanes in the skiplist, from the fastest to the slowest lane, but the analogy is limited, as there are more differences. The counter interval size is defined such that it can count all the bits in the word that contains the maximum step number. For 2^32 steps, the counter requires 5 bits, and the remaining 27 bits are data bits. For example the counter 11…11 represents the most significant bit of the word, and the counter value 00..00 represents the less significant bit.
When a data bit B is selected by the counter, then the long jump will jump to a previous step number whose binary representation has the following changes compared to the origin step:
- The bit B is cleared if set
- The bits that are more significant than B are unchanged
- The bits that are less significant than B are all set, except for the counter which is decremented by 1
If the bit B is not set in the source step number, then no long jump is available (or alternatively we can fix any arbitrary jump to any prior step). When a long jump is taken, the counter will later point to the following bit scanning from MSB to LSB. The counter continuously scans the word bits from right to left.
The following trace shows the path from step 13150 (binary 1100110101|1110), to step 3878 (binary 0011110010|0110). The pipe is used here to indicate the separation between the data bits from the counter bits. In the trace lines, the letter “J” indicates that the long jump was taken to reach that step, and “P” indicates the prior hop is a short jump (the step plus one). Next in each trace line is the number of hops in the path so far, followed by the step number and the binary representation of the step number.
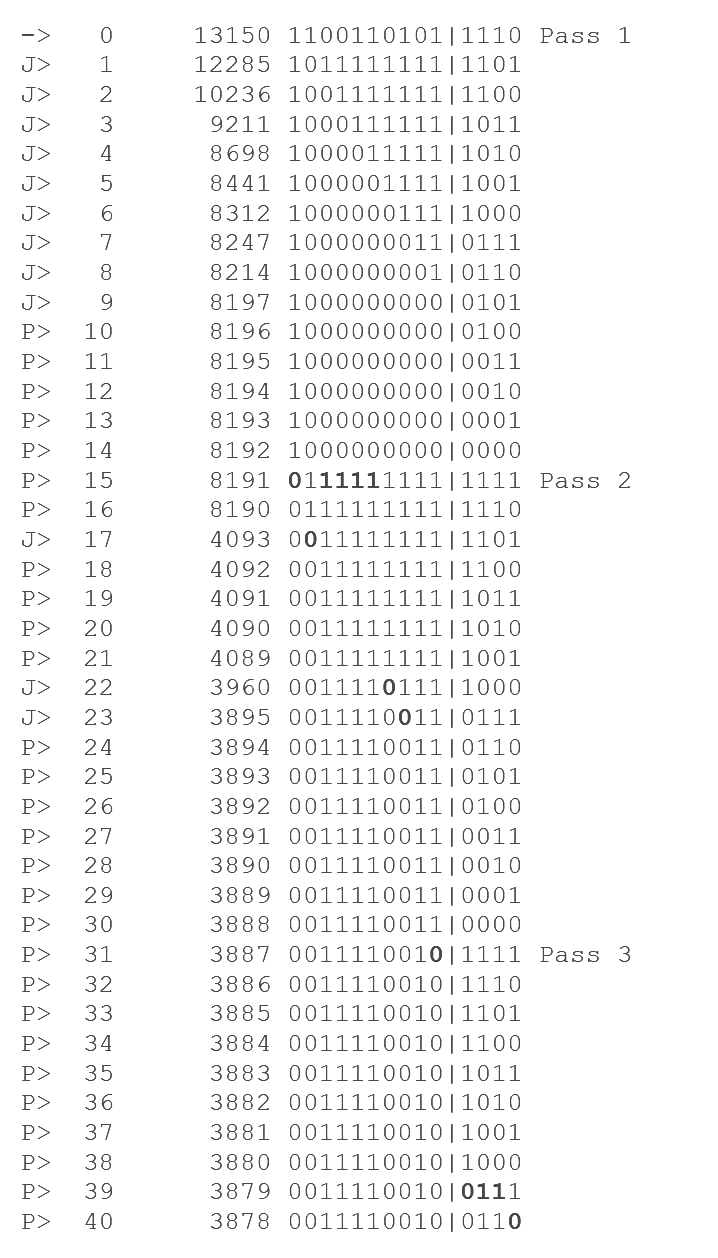
[img 8] A path from step 13150 to step 3878. In bold, the bits that are changed to match the target step. During pass 1, some data bits were cleared and the MSB bit was cleared using an underflow, but this is not required, as pass 2 goal is setting the correct data bits.
If the counter B points out of the data interval, no long jump is defined. At a first glance it may seem that our method will be unable to clear a bit that results in a jump to a step lower than the target in a single pass, but the method auto-corrects this later when the counter wraps-around zero (and the counter word underflows). When a bit is skipped, all less significant bits will be cleared, so that the following counter wrap-around zero (counter word underflow) goes as far as borrowing the skipped bit, clearing it, still in the same pass. You can see that in hop 31 of the example in the figure.
To summarize, with the presented long jump mapping, we can prove that we can traverse from any node to a previous node in at most 3log2(n)+1 hops, and 3 passes. In the worst case we’ll do:
- 1st pass: log2(n) short jumps to set the counter to point to the first data bit.
- 2nd pass: log2(n)+1 short or long jumps to change the data bits to match the data part of the target step number. This pass may need to use a counter wrap-around zero (word underflow) to clear a skipped bit.
- 3rd pass: log2(n) steps to decrease the counter to match the target pattern in the counter itself.
With a lot of algorithm tweaking, we believe it’s possible to reduce its worst case to log2(n)+3log2(log2(n)) hops. For example, there is no need to point the counter to the MSB bit, as it can be cleared by a counter underflow. Even better, we can use the counter to move over only true bits (modulo the number of true bits) instead of all bits, because only true bits can be cleared. This reduces the length of paths between low step numbers. Encoding the counter with inverted bits makes a pattern of 11..11 always point to the most significant non-zero bit, so there are more chances that the 3rd pass is not required. We can also accelerate counter reduction towards wrap-around by using the currently unused long jumps or inserting log(log(n)) extra long jumps between scanned bit positions.
An inclusion proof using the jumplist is simply a list of hash digests, from the source step down to the target step. Verifying an append proof (a new step X has the correct long jump) hash is also easy. Assuming the previous step (X-1) is correct, the prover shows an inclusion proof from (X-1) to the step number W that should be pointed by step X. Step W hash must have a commitment to its step number. The Bitcoin script must compute that step number for step X. The presented long-jump selection function is very easy to code in script when representing the numbers in nibbles and applying bitwise operations. Note that the fact that inclusion proofs are not unique doesn’t affect the protocol, as the verifier’s incentive is to post onchain the shortest inclusion path available to reduce fees.
The jumplist is very interesting as it can be used in other contexts. For example, for light clients. We can efficiently locate previous blockchain blocks when only having a single approved block tip. We introduce a consensus rule so that each block must reference not only the previous block, but an additional extra block chosen by our method. The consensus rule must check that the new link is also valid. Now proving the inclusion of a previous block is as easy as providing a path from the latest validated block to the block in question. Another related use case is proving cumulative work in a blockchain (NiPoPow). We can use our jumplist to efficiently sample pseudo-random blocks, accumulate their work, and extrapolate that sample to the whole blockchain. If we repeat this process many times, we can estimate the chain's cumulative work with higher and higher precision. The Fiat-Shamir transformation lets us turn this method into a non-interactive proof.
Summary
This is the first of a series of articles on new innovations coming from the BitVMX team. In this article we focused on techniques to reduce the number of protocol rounds. We presented 3 techniques to almost halve the number of rounds required by the BitVMX in the worst case. These are: the trace Merkle tree, the authenticated skiplist and the authenticated jumplist. The jumplist is a new data structure we created, and it’s very interesting as it provides logarithmic inclusions proofs (as the trace Merkle tree) but much simpler append proofs. In our next article we’ll present a technique to avoid posting onchain the full intermediate step hashes of the n-ary search, and the full hop list hashes in a Merkle, skiplist or jumplist inclusion proof. Instead, we’ll show how we can use truncated hashes without weakening the security. As BitVMX is a new field, innovation is the norm. Expect new ideas and papers that improve it coming in the following months. Finally, we send special thanks to Fairgate Labs and Rootstock Labs for their continued support.