Optimizing Algorithms for Bitcoin Script

When Robin from BitVM posted the
challenge on Twitter to implement SHA256 on-chain, Sergio Lerner and I
decided to take it on. Computing the hash is a crucial step for the BitVMX
protocol, so we knew it would be a valuable endeavor.
In this
article, I'll walk through the thought process that led me to optimize SHA
and Blake3. I hope that some of these ideas will help others create more
efficient Bitcoin scripts.
Later, I'll introduce a new library I
developed to aid in the implementation and debugging of these scripts. This
library allowed me to optimize Blake in just two days, compared to the two
weeks I spent on SHA2.
But First, Why Is This Needed?
The problem with Bitcoin Script is that many of its original opcodes were disabled long ago as a security measure to prevent attacks to network nodes while processing transactions. The building blocks to compute hash functions, such as bitwise operations, have been disabled. Bitcoin Script itself has an opcode, OP_SHA256, but the issue is that there is no concatenation or split opcode available to combine or split elements to be hashed, making this opcode unfit for the purpose of any optimistic protocol such as BitVM.
This problem applies not only to hashing, but also to other algorithms that require arithmetic operations. In the BitVM repository, some algorithms have been implemented using bytes as a basic unit for creating more complex data structures. For example, 32-bit operations can be constructed by operating on 4 separate bytes.
Since Bitcoin Script does support OP_IF, OP_ADD and comparison operators, most arithmetic and logic operations on unsigned 32 bit numbers can be constructed using shorter data types and standard code.
For instance, using textbook addition, if you want to add two 16-bit values, each represented with two bytes, we add the first two less significant bytes, then check if the number is greater than 256 and carry 1 if necessary, and repeat with the operation with the following more significant byte.
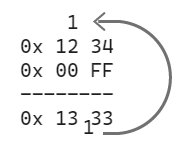
Let's see how this can be done using Bitcoin Script:
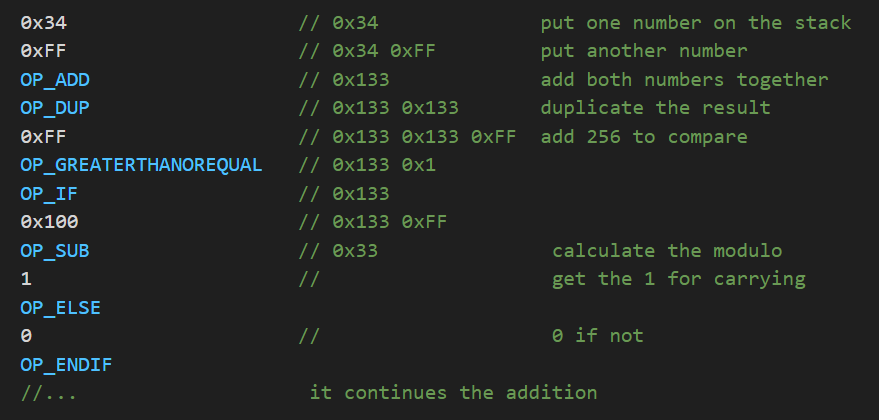
I'll introduce a notation here: on the left, I'll put the opcodes, and on the right, the stack, where the right-most element is the last one pushed
As you can see, even the simplest mathematical operation in Bitcoin Script is very costly in terms of opcodes.
Nibbles Instead of Bytes
When we faced the problem of implementing SHA-256, we soon realized that operating with nibbles would be more efficient than doing it with bytes. The idea behind using nibbles instead of bytes is that nibbles allow us to use lookup tables with pre-calculated values.
Let's say we want to shift the bits of a nibble to the right. For example, 0xE is represented by 1110 in binary format. Shifting right by 1 bit results in 0111, which equals 0x7.
So, we can pre-calculate the table of results for shifting each nibble value from 0 to 15 to the right by 1 bit. The table can be easily generated in any language; I used Python for simplicity:

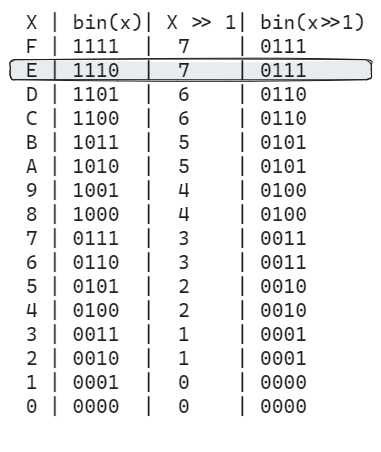
And then, to get the result, we just need to obtain the proper offset inside the table. Note that the table is generated in reverse, as the pick operation uses the depth in the stack to obtain the position of the result.

It's also possible to use lookup tables when operating with bytes for some operations, but the problem is that for this same operation, the table using bytes would have 256 elements instead of 16. When the type of operation requires two operands, like XOR, you need 16*16 = 256 elements using nibbles, and 256*256 = 65,536 elements using bytes.
Besides the on-chain cost associated with using such a long script, there is a stack limit of 1,000 elements, which forbids using long tables. The stack limit represents a very challenging constraint, and it’s generally overlooked.
Understanding SHA256
I have used this hashing algorithm many times in the past, but I had never needed to understand how it works internally. Fortunately, it's not very hard, and there are plenty of resources available. Wikipedia provides a pseudocode that is easy to follow, and there’s also this awesome page https://sha256algorithm.com/ that allows you to execute the algorithm step by step and observe all its internal values.
At a very high level, the algorithm processes chunks of 512 bits of data per round and produces a 256-bit hash. If the information to be hashed is less than 512 bits, it adds some padding to complete the block. Internally, it organizes the data into 32-bit integers.
The process involves two loops. In the first loop, which has 48 rounds, it expands the message from 16 registers of 32 bits (16x32=512) into 64 registers of 32 bits. In the second loop, which has 64 rounds, it mixes the 64 registers to produce a 256 bit output.
The basic operations used during the algorithm are XOR, AND, addition, right rotation (also called circular shift, where the bit coming out from the right gets back in on the left), and standard shifting.
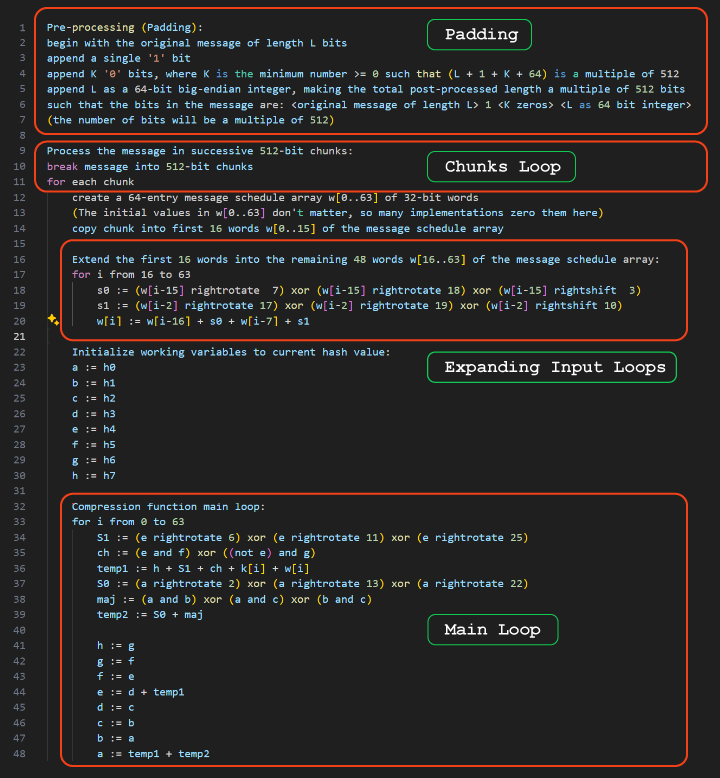
Creating lookup tables
Right and Left shift
I started with the shift operations as they only require operating with one number at a time. You can use the same Python snippet previously mentioned to generate shift right and left operations for 1, 2, and 3 positions. Since we are operating with 4 bits, the 4th shift is not required as it only involves moving the position of the whole nibble. Any shift greater than 4 bits is solved by a shift modulo 4 and a nibble reposition.
When you need to shift two nibbles together, to get on the less significant nibble the bits shifted from the most significant nibble, it is a bit more complex. For example, if you want to compute 0x32 shifted 1 to the right, you would need a table of two elements.

But there is also the possibility to use this transformation which uses two
tables instead of one. One to shift left the most significant nibble and one
to shift right the less significant one, and then adding both together using
OP_ADD, which we already have in Bitcoin script:
YX >> 1 == (Y << 3 + X>> 1) & 0xF

Logic tables (XOR,AND,OR)
Now I show how to implement the bitwise logic operations with different methods: simple lookup and double lookup.
Simple Lookup
The first approach was to create a table of 256 elements where the two nibbles you want to operate are “concatenated”. For instance, if you want to calculate 0xF AND 0x1 = 0x1. Then you can shift left the 0xF with one table to convert it to 0xF0, then add the second nibble: 0xF0 + 0x1 = 0xF1. You can then use this value (0xF1=241) as the position in the table to obtain the result (0x01).
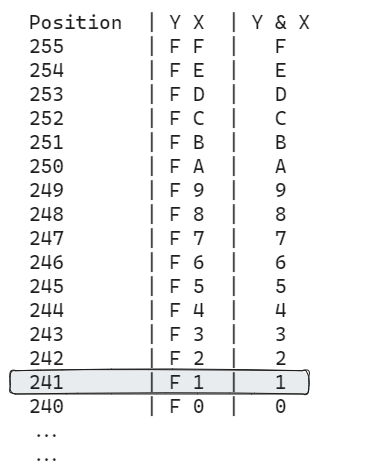
Double Lookup
This method was ok, but I wanted to achieve shorter lookup codes so I decided to try something else. The next approach was to use 16 tables of 16 elements, plus a second lookup table. The idea is that each of the 16 tables contains the result of a specific Y value against the 16 possible X values. The second lookup table contains the offset of each of these individual tables.
So, if you want to calculate 0x5 & 0x3, you first use the lookup table to find the position of the table for 0x5 & X. Then, you add this result to 0x3 to obtain the position and use OP_PEEK to get the result.
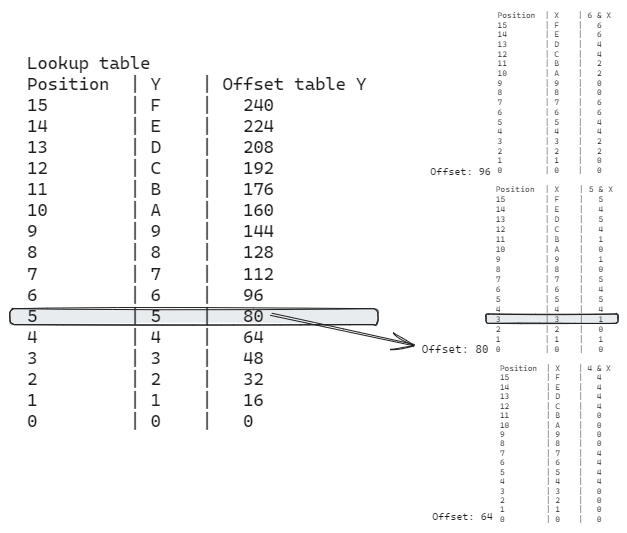
The actual tables and space used are almost the same, although I think this approach also saves some opcodes. The real benefit is that it allows the creation of “half tables”.
Stack Limit Gotcha
When I was working on creating the tables, I initially created and tested each table independently, and everything worked very well. However, when I tried to load all the tables together, it didn’t work. It's important to emphasize that in Bitcoin script there is a stack limit of 1,000 elements. While I was focusing on optimizing the number of opcodes, I completely overlooked this constraint. This realization led me to explore more efficient methods for utilizing the stack.
Half Tables
After hitting the stack limit, I started thinking about how to optimize the elements on the stack.
I realized that since logical operations are commutative ( x & y == y & x ), I could save almost half of every logic table.
For instance, I have the table for Y = 0 and the results for X from 0 to 15. Then for Y = 1, there’s no need to include the result of X = 0 as it is already in the previous table. By the time you get to the table for Y=15, you only need one element, X=15.
While this technique almost halves the number of elements in the stack, it has the drawback of needing to sort the element Y and X before accessing the tables. This can be done in bitcoin script using OP_MAX and costs 5 opcodes.
After adjusting the lookup table to point to the right offset, I managed to reduce 256 elements to 136 at the expense of some additional operations to sort the nibbles.
XOR With AND
At some point while advancing on the implementation of the algorithm, I found
that having the XOR and the AND table on the stack sometimes exceeded the
stack limit.
To address this, I started using an alternative method to calculate XOR
using AND.
This is the logic equivalence:
(a xor b) = (a + b) - 2*(a and b)
I then refactored the equivalence to better accommodate to the nature of the
stack and bitcoin script:
b - 2(a and b) + a
This results in the following script (assuming that a and b are already on the stack):
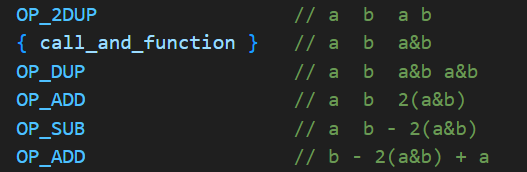
Addition
When I started with the hash algorithm, I left the addition operation to the end because I thought that, given OP_ADD is available, it would be easy and cheap compared with the bitwise logic operations. I was wrong. The challenge arises because it’s necessary to handle the carry when the sum of two nibbles overflows.
This means that when A + B > 15, a lot of extra operations are needed.
One interesting aspect of the SHA-256 algorithm is that it needs to add several u32 numbers simultaneously. In logic circuits, you can often take advantage of this using a carry-save adder. Preparing the numbers for addition requires arranging the nibbles from two different u32 numbers intercalated in the right order so the addition can be performed. Given these operations are costly, I realized that adding several numbers at once would reduce the cost.
For example if you have Z = A + B + C + D, normally you would need to arrange the nibbles of A and B, then perform the addition operations. Then take this result and arrange the nibbles with C, perform the operations, and then one more time with D. This requires arranging 6 numbers. If you compute the addition at the same time, you only need to arrange A, B, C and D one time. However, the number of operations is still very high.
Then I found a way to use tables for this, if I add 4 nibbles together the maximum number would be 60, plus 3 of carrying other numbers (4 * 0xF + 3).
I then need two tables: one for a number modulo 16 and one for the quotient of a number when dividing by 16.

Juggling With Tables
As I mentioned previously, the stack limit was a crucial factor in choosing which tables to use. Developing different alternatives helped balance the total cost of the script while being able to keep the tables in the stack.
For example, when processing messages longer than 55 bytes, which required the message to be split into two chunks, the addition tables did not fit in memory, so I resorted to pure script computation. However, for smaller messages, I was able to load those tables.
Another case was the XOR and XOR with AND operations. As the main loop uses both operations, it was necessary to keep the AND table in the stack and compute XOR using AND. However, since the input expansion loop only uses XOR, I found it was cheaper to start with the XOR table in the stack, calculate the first round, then unload the XOR table, load the AND table, go through the main loop, and then switch back to the original state if there was another chunk to process.
SHA256 Specific Optimizations
When analyzing the original implementation of an algorithm from another
language to be implemented in Bitcoin Script, it's important to consider
that these algorithms are usually optimized for normal CPUs. Any standard
CPU has huge amounts of RAM, and the access time to any position is
constant, contrary to bitcoin script, where the stack limit is 1000
elements, and accessing an element in the middle of the stack requires at
least 2 or 3 opcode bytes.
Also the code is generally optimized for cache locality, pipelining, and
other methods that are not applicable on Bitcoin Script. Therefore, just
translating the normal implementation will not work as the costs are
completely different on Bitcoin Script.
Splitting The Padding
Usually, adding the padding bytes to the message is a preliminary step before splitting the message in chunks and processing them. When there is only one chunk, this is fine, and on a normal CPU (without stack limit), it would be fine too, as it only adds a small number of bytes. However, for longer messages that require hashing more chunks, having those extra bytes on the stack makes a significant difference on which tables can be loaded on the stack.
One specific optimization was to compute the part of the padding necessary for the first chunk (if any) and add that part to the stack. After processing the first chunk, when the first 64 bytes are no longer on the stack, the rest of the padding is added to the second chunk.
There were some edge cases to consider, but that extra space on the stack was crucial.
Majority and Choice
In the main loop of the SHA-256 algorithm, there are two specific parts called "majority" and "choice," where several logic operations are applied.
This is definition of choice:

And this the definition of majority:

The Wikipedia article (of sha-1 that is common to both) shows some alternatives for computing these values, as there are several possible logical transformations.
I chose an option (shown in the graph below) that I believe gave good results, even though I did not exhaustively try all the alternatives. One interesting characteristic of these operations is that, unlike addition or rotation which move the bits within the 32-bit word, the bitwise logical operations do not. When there are multiple operands, this allows for the application of all the operations to all the nibbles in one column position simultaneously before considering the next nibble.

Moving Instead of Copying
One last improvement I made once the algorithm was completed was to identify places where the elements on the stack were used for the last time. In those places, instead of copying the values, I moved them. Bitcoin Script has two opcodes related to this: OP_PICK and OP_ROLL. Both opcodes take an argument that specifies the depth on the stack of the element to be copied or moved.
This sounds simple, but consider the difference in indices when you want to copy versus move a variable. Now imagine you need to arrange the elements of two different numbers in two different positions on the stack, and you want to move one and copy the other. In this case, the size of the stack shrinks differently at different positions.
Calculating these values (mentally) was the most time-consuming part and the most difficult to debug in the first implementation. I attempted to create a helper to track this, but it was not clear or easy to generalize. I also saw a similar attempt made in the Blake3 implementation of BitVM, but it felt too specific.
This is why I decided to create the bitcoin-script-stack library, to help me automatically track these positions and simplify the development of Bitcoin Script in general.
Summary
In this article, I presented several techniques that allowed me to reduce the script size of the on-chain implementation of SHA256 from 516K opcodes to 344K. We explored the use of nibbles instead of bytes, the application of lookup tables, and other tricks specific to SHA256.
In the next article, I’ll introduce a library that led to an additional reduction from 344K to 296K for SHA256. I'll also cover the details of implementing Blake3, where I managed to reduce the size from 103K to 75K ( 1 ), and demonstrate how to use this library to simplify the development and debugging of Bitcoin Scripts.
( 1 ) Due to an error in how I computed the script length, I initially thought it was 45K, but it ended up being 75K. (With further optimizations not covered in this articles I managed to reduce it to 69K).